작년 봄에 Kubernetes 에 대해 간단히 설명하는 글을 썼었는데, 그때는 컨테이너 오케스트레이션 플랫폼을 한번도 써본적이 없는 상태에서 스터디 발표주제를 Kubernetes로 정하고, 생소한 개념들을 조사하고 정리했었다. 당시에는 오케스트레이션 플랫폼이 왜 필요한지 아직 크게 와닿지 않았었는데 작년에 다니던 회사에서 Amazon ECS 를 처음 써보게 되면서 어렴풋이나마 컨테이너 오케스트레이션의 필요/중요성에 대해서 알게된 것 같다.
컨테이너는 stateless, immutable, mortal (상태를 가지고 있지 않고, 변화하지 않으며, 언제든 죽을 수 있는) 하다. 는 개념을 기반으로 아키텍처를 구성하다 보면 운영에 앞서 반드시 필요한 것이 컨테이너 오케스트레이션이라고 생각한다.
컨테이너 오케스트레이션은 다수의 컨테이너를 다수의 호스트(클러스터)에 적절하게 분산 실행하고, 원하는 상태(desired state)로 실행상태를 유지해 주고, 다운타임 없이 유동적으로 스케일을 확장/축소할 수 있게 도와주며, 컨테이너의 라이프 사이클 및 컨테이너/호스트간 연결을 관리해주는 컨테이너 지휘자 혹은 매니징 서비스/플랫폼이라고 이해하고 있다. 간단히 말해 사용자가 컨테이너에 대한 동작과 다른 컨테이너와의 관계를 정의하면 배포/운영/스케일링에 문제가 없도록 자동으로 관리되는 운영 시스템이라고 할 수 있겠다.
ECS를 사용하면서 다른 컨테이너 오케스트레이션 플랫폼에도 관심을 가지게 되었고 그 중에 역시 Kubernetes에 대해 좀 더 알아보고 싶은 생각이 있었는데, 얼마 전부터 스터디에서 Kubernetes를 공부하게 되서 이 기회에 새롭게 공부한 내용을 블로그에 정리해 보려고 한다.
시작하는 욕심으로는 일단 기본적인 이론을 정리하는 글을 먼저 작성하고, 틈틈히 실습하면서 잘못 이해했던 내용들도 업데이트하려고 하는데, 글을 쓰는 이 시점에도 매일 매일 어제까지 알던 내용이 오늘 새롭게 배운 내용으로 업데이트 되고 있어 부족한 부분이 많을 것으로 생각한다. 혹 틀린 부분이 있다면 거침없이 리플을 달아주시면 함께 공부해 가는데 도움이 될 것 같다.
자 그럼 시이작!
Kubernetes
Kubernetes 공식 사이트의 What is Kubernetes? 페이지를 보면 Kubernetes를 다음과 같이 설명하고 있다.
Kubernetes is an open-source platform designed to automate deploying, scaling, and operating application containers.
Kubernetes는 어플리케이션 컨테이너의 배포 자동화, 스케일링, 운영을 위해 설계된 오픈소스 플랫폼이다.
비슷한 목적으로 만들어진 몇개의 플랫폼으로는 Docker Swarm, Hashicorp Nomad, Mesosphere Marathon, Amazon ECS 등이 있어 컨테이너 오케스트레이션 플랫폼의 자웅을 겨뤄왔었는데 최근에는 Amazon AWS 에서 EKS 서비스를 발표하는 등 Kubernetes가 컨테이너 오케스트레이션에서 사실상의 표준(de facto standard for container orchestration) 의 자리를 차지하게 된 것으로 보인다.
잠깐 Kubernetes의 역사를 살펴보면 약 10여년 전 Google에서 대량의 Container 관리를 위해 Borg라는 이름의 프로젝트가 시작되었고 Borg 플랫폼의 주요멤버들이 Borg에서 Pod, Service, Label등의 주요 설계를 차용해서 Seven(스타트렉의 캐릭터) 이라는 코드명의 신규 프로젝트 개발을 시작하게 되었고 그 결과물이 2014년 Kubernetes라는 이름으로 외부에 발표되었다.
Kubernetes는 그리스어로 배의 조타수를 의미하고 영문표기는 Helmsman이다. (Kubernetes 클러스터에 서비스 단위로 프로비저닝/배포를 자동화한 Package Manager의 이름이 Helm이다.)
Kubernetes는 2016년 CNCF (Cloud Native Computing Foundation)에 첫 번째 프로젝트로 기부되었다. CNCF에는 Kubernetes를 포함해 Prometheus, GRPC, OPEN TRACING, fluentd, envoy 등 굵직한 오픈소스 프로젝트들이 소속되어 있다.

Kuberentes는 100% 오픈소스로 Go언어를 사용해서 개발되었다. 저장소는 GitHub에서 확인할 수 있다.
2018년 2월 현재 버전은 1.9로 유지되고 있으며 Docker와 CoreOS의 rkt 컨테이너를 지원한다.
Kubernetes의 글자 수가 길어서 그런지 시작하는 K와 중간의 8글자(ubernete) 그리고 끝의 s를 붙여 K8s로 표현하기도 한다. 앞으로는 이 두개를 혼용해서 설명하려고 한다. 읽을 때는 쿠버네티스 혹은 쿠베(이건 외국에서도 통할지는 모르겠다.) 라고 줄여 발음하고 있다.
Pod
K8s에 대한 설명에 앞서 먼저 Pod 을 이해하고 넘어갈 필요가 있다.
Pod은 K8s의 가장 작은 배포 단위(Unit)로 K8s에서는 컨테이너가 가장 작은 배포단위가 아니라 Pod이 가장 작은 배포단위로 취급된다. 는 점이 중요하다.
Pod은 다음과 같은 특징을 가지고 있다.
- 1개의 Pod은 내부에 여러개의 컨테이너를 가질 수 있지만 대부분 1~2개의 컨테이너를 갖게 된다.
- 1개의 Pod은 여러개의 물리서버에 나눠지는 것이 아니고 1개의 물리서버(Node) 위에 올라간다.
- Pod 내부의 컨테이너들은 네트워크와 볼륨을 공유하기 때문에 localhost 로 통신할 수 있다.
- Pod은 클러스터 내에서 사용할 수 있는 유니크한 네트워크 ip를 할당 받지만 이 ip는 서비스에서 사용하지 않는다.
이는 K8s에서 Pod은 언젠가는 반드시 죽는(mortal) 오브젝트이기 때문이다.이후에 설명하겠지만 Service라는 오브젝트에서죽기도하고 또 다시 살아나기도 하는 Pod의 Endpoint를 관리하고 Pod의 외부에서는 이 ‘Service’ 를 통해 Pod에 접근하게 된다. - 동일 작업을 수행하는 Pod은 ReplicaSet이라는 컨트롤러에 의해 정해진 룰에 따라 복제된다. 이때 복수의 Pod이 여러개의 Node에 걸쳐 실행될 수 있다.
Pod의 속성인 mortal은 mortal kombat의 그 mortal …
Kubernetes의 특징
Kubernetes는 다음과 같은 특징을 가지고 있다.
- Automatic binpacking
가용성을 희생하지 않는 범위안에서 물리적 리소스를 충분히 활용해서 Pod을 (자동) 배치한다.
여기서 binpacking이란 컨테이너가 호스트의 물리적 리소스를 충분히 활용할 수 있도록 효율적으로 고르게 배치해서 불필요한 물리적 리소스의 낭비를 줄이는 것을 의미한다.
캠핑갈 때 비좁은 트렁크에 캠핑용품을 이러저리 잘 정리해서 빈공간 없이 테트리스해서 쌓아 넣는 모습을 상상했다.
- Self-healing
Container의 실행 실패, Node(K8s에서 Pod을 실행하는 슬레이브 호스트)가 죽거나 반응이 없는 경우, health check에 실패한 경우에 해당 Container를 자동으로 복구한다. Kubernetes가 관리하는 가장 작은 배포단위인 Pod은 언젠가는 반드시 죽는(mortal) 것으로 정의되어 있으며 Contianer, Node의 장애 상황발생 시에도 운영자가 기대하는 상태로 서비스가 무사히 실행될 수 있도록 Self-healing을 지원한다. - Horizontal scaling
Pod의 CPU 사용량 혹은 app이 제공하는 metric을 기반으로 ReplicaSet (동일한 Pod을 몇 개 띄울지 정의) 을 scailing할 수 있다. - Service discovery and load balancing
익숙하지 않는 Service Discovery 매커니즘을 위해 Application을 수정할 필요가 없다. K8s는 내부적으로 Pod에 고유 IP, 단일 DNS를 제공하고 이를 이용해 load balancing 한다. - Automated rollouts and rollbacks
application, configuration의 변경이 있을 경우 전체 인스턴스의 중단이 아닌 점진적으로 Container에 적용(rolling update) 가능하다. Release revision이 관리되고 새로운 버전의 배포시점에 문제가 발생할 경우 자동으로 이전의 상태로 Rollback을 진행할 수 있다. - Secret and configuration management
Secret key, Configuation을 관리하기 위해 Secret, ConfigMaps Object가 제공되기 때문에 이미지의 변경없이 키/설정을 업데이트할 수 있고, 이를 외부에 노출(expose)하지 않고 관리/사용할 수 있다. Secret은 데이터를 binary 형태로, ConfigMap은 text 형태로 저장한다. - Storage orchestration
local storage를 비롯해서 Public Cloud(GCP, AWS), Network storage등을 구미에 맞게 자동 mount할 수 있다.
지원하는 storage volume type은 다음과 같다.
awsElasticBlockStore, azureDisk, azureFile, cephfs, configMap, csi, downwardAPI, emptyDir, fc (fibre channel), flocker, gcePersistentDisk, gitRepo, glusterfs, hostPath, iscsi, local, nfs, persistentVolumeClaim, projected, portworxVolume, quobyte, rbd, scaleIO, secret, storageos, vsphereVolume
지금도 많지만, 지원하는 volume type이 계속 추가되고 있다.
- Batch Execution
batch, CI 작업의 수행을 관리할 수 있다. 원한다면 배치실행 실패 시 container를 교체하는 것도 적용 가능하다.
이에 더해 K8s는 독립된 Container로 구성된 집합이기 때문에 특정한 환경 (bare metal 이나 public/private cloud)에 종속되지 않고, 다양한 네트워크, 볼륨 플러그인 등이 제공되어 쉽게 다른 환경으로 이식할 수 있다는 장점을 가지고 있다.
Master and Node(Minion)
K8s 클러스터는 크게 K8s 클러스터의 모든 상태를 저장/관리하는 Master와 실제 Pod을 운용하는 Node로 구성된다. Node는 Minion이라고 표현하기도 한다.
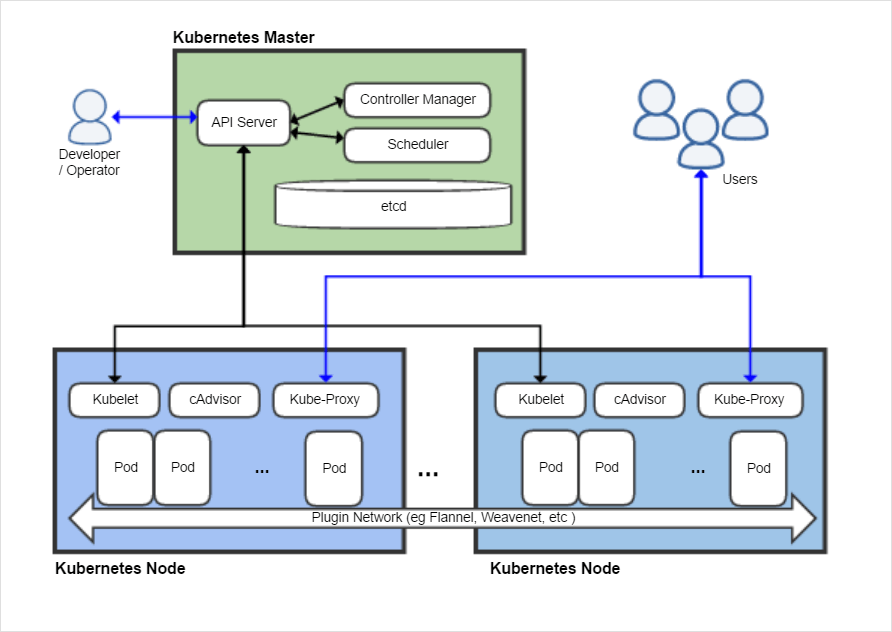
from https://en.wikipedia.org/wiki/Kubernetes
그림의 아키텍처를 참고해서 Master와 Node의 주요 리소스에 대해서 알아보자.
Master
Master는 다음과 같은 K8s 컴퍼넌트로 구성된다.
- API Server
- Controller Manager
- Scheduler
- etcd
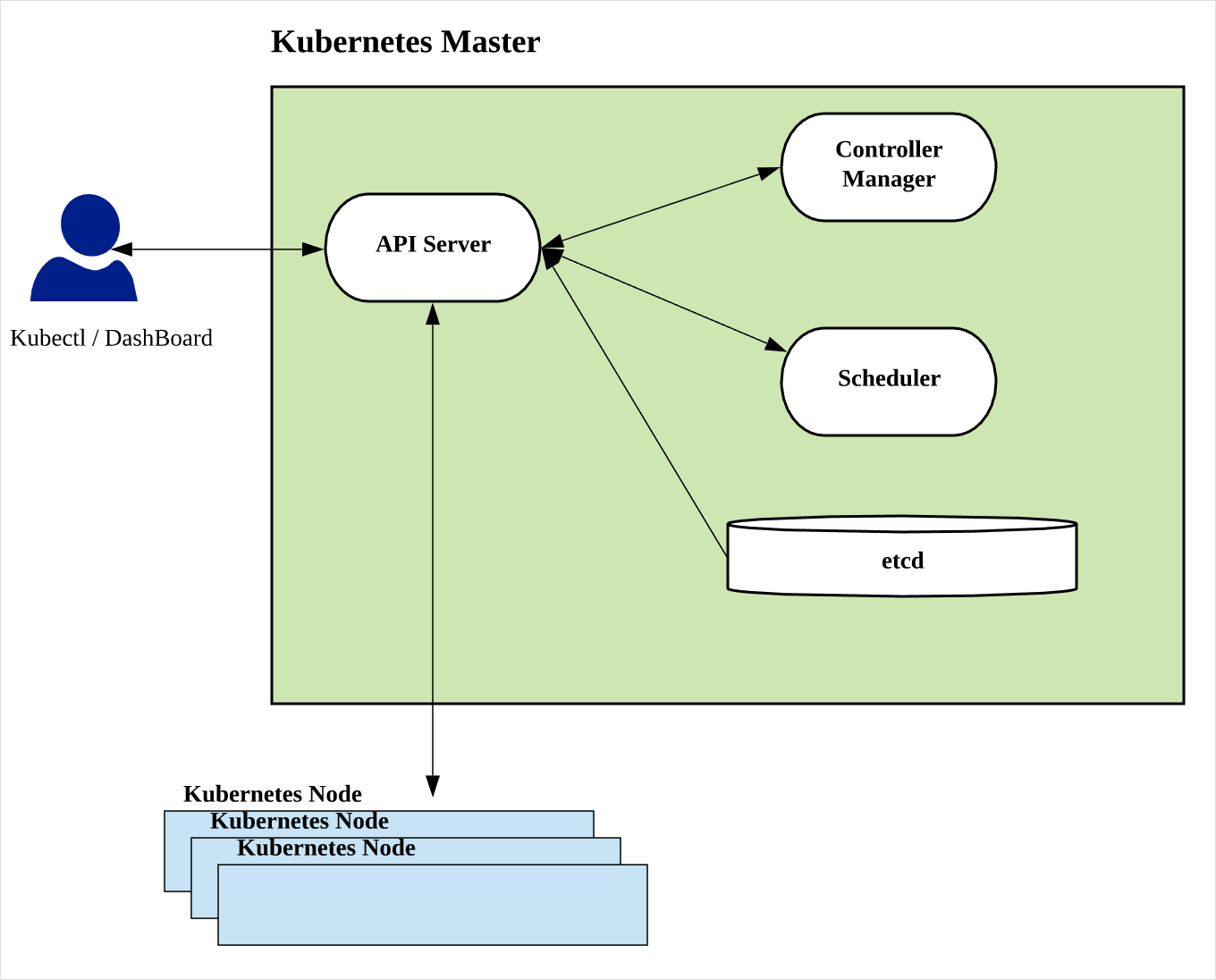
Master의 각 컴퍼넌트의 역할은 다음과 같다.
API Server
K8s에서 가장 중요한 컴퍼넌트이다.- K8s 내부의 모든 동작은 HTTP/HTTPS REST API를 통해서 호출된다.
- 각각의 K8s 컴퍼넌트가 서로 직접 연결된 형태가 아니고
모든 컴퍼넌트는 API Server를 경유해서 통신한다. - 컴퍼넌트들은 API Server를 watch하고 있다가 자신과 관련된 부분의 변경사항이 있으면 변경사항을 업데이트하는 형태로 구현되어 있다.
- 앞단에 Pluggable하게 인증시스템을 붙일 수 있다.
- K8s, GKE 개발에 참여했던 @jbeda님의 블로그 글에서 아래 플로우 다이어그램을 보면 모든 요청은 API Server를 경유해서 각 컴퍼넌트로 전달되고 있음을 확인할 수 있다.
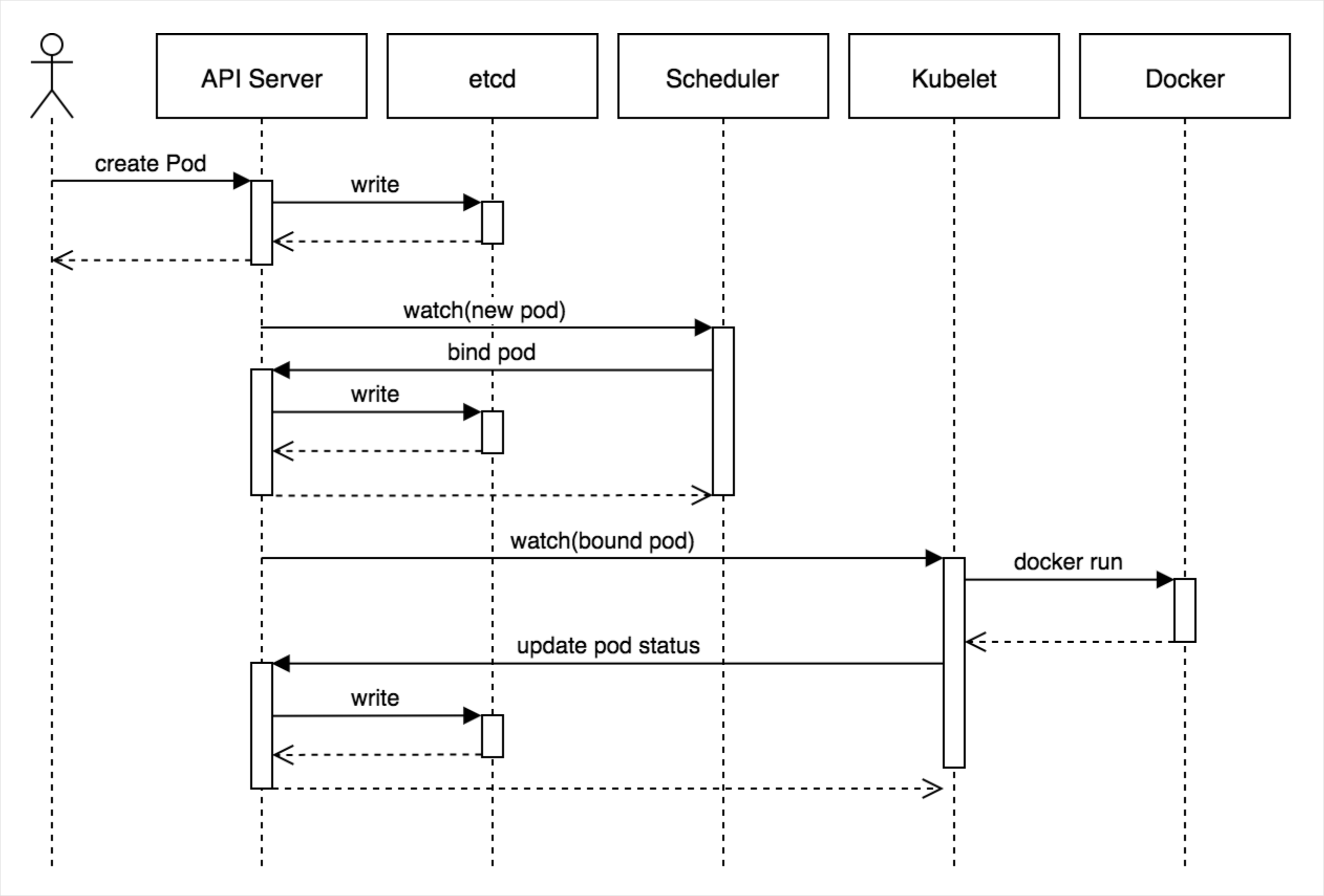
from: Core Kubernetes: Jazz Improv over Orchestration - kubectl (Kubernetes command-line tool)이나 GUI Dashboard에서 명령을 실행할 때도 REST API를 통해 Master의 API Server에 API를 호출하는 형태로 수행된다.
- 클러스터 정보를 저장하는 etcd에도 각 컴퍼넌트가 직접 접속하지 않고, API Server가 etcd의 watch와 유사한 기능을 구현하고 컴퍼넌트들은 API Server를 watching하게 된다. (소스를 잠깐 살펴보면 API Server가 etcd에서 받은 데이터를 대상 컴퍼넌트에 go언어의 Channel을 통해서 토스한다.)
좀 더 자세한 설명은 Kubernetes Master Components: Etcd, API Server, Controller Manager, and Scheduler 글에서 확인할 수 있다.
Controller Manager
- K8s에서 ReplicaSet, Deployment등의 Controller는 Pod의 복제/배포를 변경하는 명령을 수행하고 Pod의 상태를관리한다.
- Controller Manager는 이 Controller들을 데몬형태로 포함하고 있다.
- Controller Manager는 Pod의 상태를 항상 기대하는 상태로 유지한다.
Scheduler
- 어떤 Pod을 어떤 Node에서 실행할 지 결정한다.
- 각 Node의 자원 사용 상황, 노드당 클러스터 분배 비율을 기반으로 컨테이너를 배치한다.
- Node에 배치된 Pod은 아래 설명할 각 Node의 Kubelet 컴퍼넌트에 의해 컨테이너로 생성된다.
etcd
- 분산 키/밸류 저장소
- 클러스터 설정 및 현재 상태(클러스터의 각 노드, 노드에서 동작중인 Pod 등의 모든 상태)를 저장한다.
- Service Discovery에서 사용하는 SkyDNS의 데이터를 저장한다.
Node (minion 이라고도 한다.)
Node는 다음과 같은 Component로 구성된다.
- Kubelet
- cAdvisor
- Kube-Proxy
- Pod
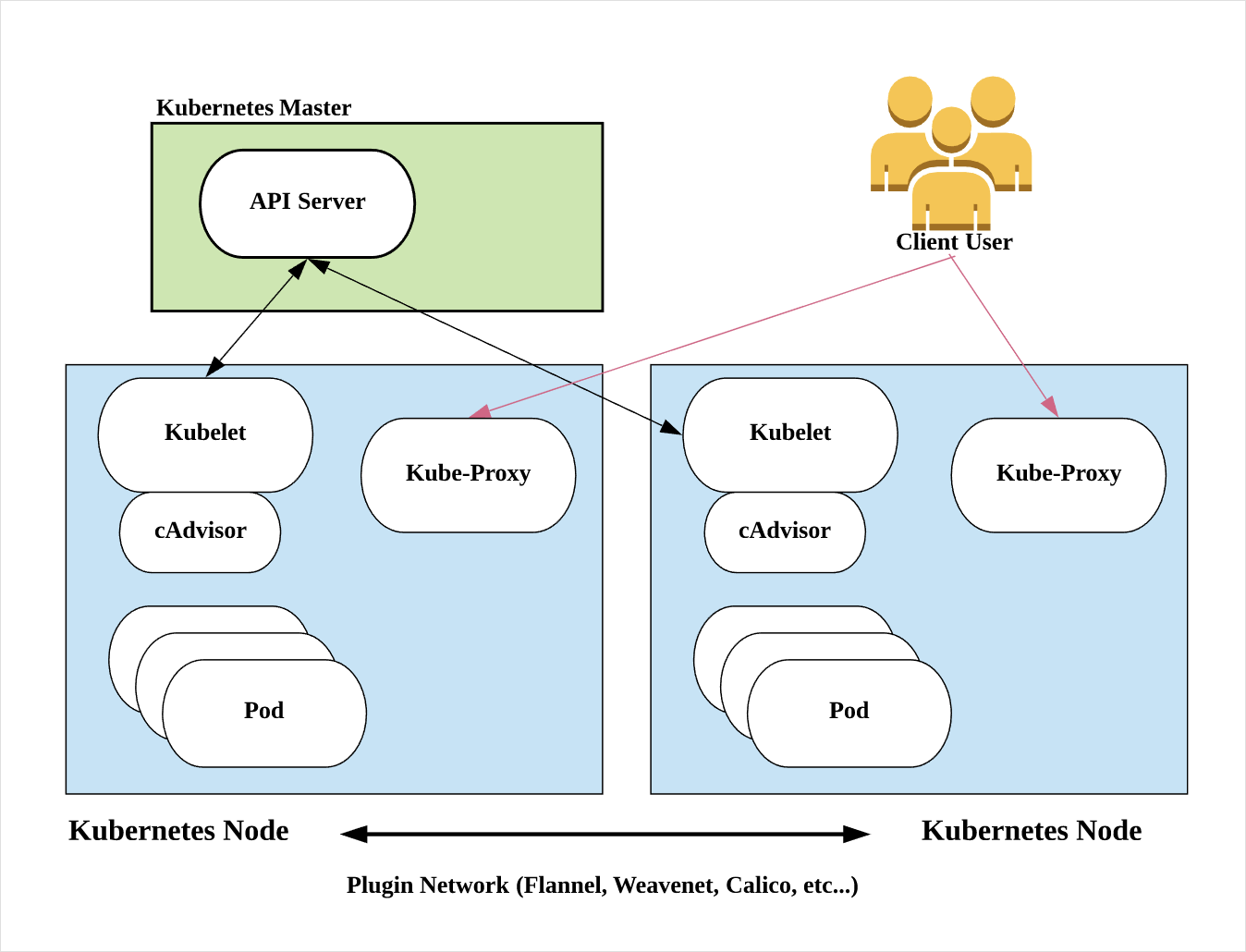
Node의 각 컴퍼넌트의 역할은 다음과 같다.
Kubelet
- Node마다 한개씩 떠있는 Node(worker) Agent라고 할 수 있다.
- Service, Pod을 실행/중지하고 desired 상태를 유지시킨다.
- 주기적으로 API Server에 Node의 상태를 Check & Report access 한다.
cAdvisor
- 동작중인 컨테이너의 리소스 사용량과 퍼포먼스를 모니터링 한다.
- 모니터링한 결과는 Kubelet에 의해 Master의 API Server로 전달된다.
- Gihub에서 프로젝트를 확인할 수 있다.
Kube-Proxy
- 네트워크 프록시 + 로드밸런서의 역할을 한다.
- 외부의 요청을 분산되어있는 Pod으로 전달한다.
- 여기에 대해서는 Kubernetes Networking을 주제로 좀 더 자세한 글을 작성할 예정이다.
- 컨테이너간의 통신을 위해서 iptables rules를 변경한다.
Pod
- 위에서 설명했던 K8s의 가장작은 배포단위인 Pod이다.
- K8s의 가장작은 단위가 컨테이너가 아닌 Pod 임을 이해하는 것이 전체 아키텍쳐를 이해하는데 도움 된다.
Pod은 몇번이고 다시 설명해도 좋으니…다시 한번 설명하면
Pod은 K8s의 가장 작은 배포 단위(Unit)로 K8s에서는 컨테이너가 가장 작은 배포단위가 아니라 Pod이 가장 작은 배포단위로 취급된다. 는 점이 중요하다.
Pod은 다음과 같은 특징을 가지고 있다.
- 1개의 Pod은 내부에 여러개의 컨테이너를 가질 수 있지만 대부분 1~2개의 컨테이너를 갖게 된다.
- 1개의 Pod은 여러개의 물리서버에 나눠지는 것이 아니고 1개의 물리서버(Node) 위에 올라간다.
- Pod 내부의 컨테이너들은 네트워크와 볼륨을 공유하기 때문에 localhost 로 통신할 수 있다.
- Pod은 클러스터 내에서 사용할 수 있는 유니크한 네트워크 ip를 할당 받지만 이 ip는 서비스에서 사용하지 않는다.
이는 K8s에서 Pod은 언젠가는 반드시 죽는(mortal) 오브젝트이기 때문이다.이후에 설명하겠지만 Service라는 오브젝트에서죽기도하고 또 다시 살아나기도 하는 Pod의 Endpoint를 관리하고 Pod의 외부에서는 이 ‘Service’ 를 통해 Pod에 접근하게 된다. - 동일 작업을 수행하는 Pod은 ReplicaSet이라는 컨트롤러에 의해 정해진 룰에 따라 복제된다. 이때 복수의 Pod이 여러개의 Node에 걸쳐 실행될 수 있다.
여기서는 대충 개념을 이해하고, 이후에 실제 Pod을 생성해서 실습을 한번 하고 나면 짠! 하고 이해가 될 것으로 생각한다.
Network Plugin
- Cluster 내부의 Overlay Network는 다음의 플러그인 중 선택해서 사용할 수 있다.
Cluster Networking ACI, Cilium, Contiv, Contrail, Flannel, Google Compute Engine (GCE), Kube-router, L2 networks and linux bridging, Multus (a Multi Network plugin), NSX-T, Nuage Networks VCS (Virtualized Cloud Services), OpenVSwitch, OVN (Open Virtual Networking), Project Calico, Romana, Weave Net from Weaveworks, CNI-Genie from Huawei
정리
K8s의 소개, 특징 그리고 K8s를 구성하는 Master, Node의 각 컴퍼넌트의 역할에 대해 설명했다.
다음 글에서는 K8s의 주요 개념인 Pod, Namespace, ReplicaSet, Service, Deployment 등의 개념에 대해서 알아보고, 실제 K8s 테스트 환경에 도커 컨테이너를 올려보는 실습을 통해 K8s의 주요 object, controller에 대해서 소개할 예정이다.
같이 공부를 시작한 입장에서 어서 K8s를 사용해보고 싶어! 하고 타오른 열정이 식기전에 다음 글을 빨리 올릴 수 있도록 노력하겠다. 글이 조금이라도 도움이 되었다면 응원 부탁드린다. 🙂