지난 글 Kubernetes Intro 에서는 K8s(Kubernetes)의 Master와 Node(Minion)를 구성하는 주요 컴퍼넌트에 대해서 설명했었다.
이어서 K8s 클러스터의 주요 개념인 Object와 Controller에 대해서 설명하기로 예정되어 있었는데 글이 너무 늦어졌다. (근 한달 가까운 시간을 푹 쉬었…혹시 기다리셨던 분이 계시면 죄송합니다. ㅠ_ㅠ 이제 살아났어요!!)
Object, Controller
Object는 K8s의 상태를 나타내는 엔티티를 의미한다. 따라서 Object는 K8s API의 Endpoint로서 동작한다.
각각의 Object는 Spec과 Status라는 필드를 갖게되는데 K8s는 Object의 Spec을 통해 사용자가 기대하는 상태(Desired State)가 무엇인지 알 수 있고, 기대되는 값에 대비한 현재의 상태를 Object의 Status를 통해 알 수 있다.
이 때 Object의 Status를 갱신하고, Object를 Spec에 정의된 상태로 지속적으로 변화시키는 주체를 Controller라고 한다.
Object에는 Pod, Service, Volume, Namespace등이 포함되고
Controller에는 ReplicaSet(구 ReplicationController), Deployment, StatefulSets, DaemonSet, CronJob 등이 포함된다.
앞으로 K8s의 주요 Object와 Controller에 대해 설명할 예정인데, 그 시작으로 먼저 Pod Object에 대해서 알아보자.
Pod
K8s의 역할을 간단히 요약하면 뭐라고 말할 수 있을까?
나는 그 해답을 유튜브 동영상 Kubernetes in 5 mins – Vmware Cloud-Native 에서 찾았다.
동영상에서 설명하듯이 K8s의 주된 역할은 Desired State Management라고 할 수 있다.
사용자가 정의한 설정(파일)에 맞춰 클러스터 자원을 효율적으로 사용해서 (땡땡땡을) 사용자가 기대하는 상태로 동작하도록 생성하고 실행 상태를 안정적으로 유지해주는 것이다.
여기서 이 땡땡땡에 해당하는 부분이 바로 Pod(팟)이다.
Pod은 K8s가 상태유지를 위해 사용하는 가장 작은 배포단위를 의미한다.
K8s의 가장작은 배포단위가 컨테이너가 아닌 Pod임을 기억하고 넘어가자.
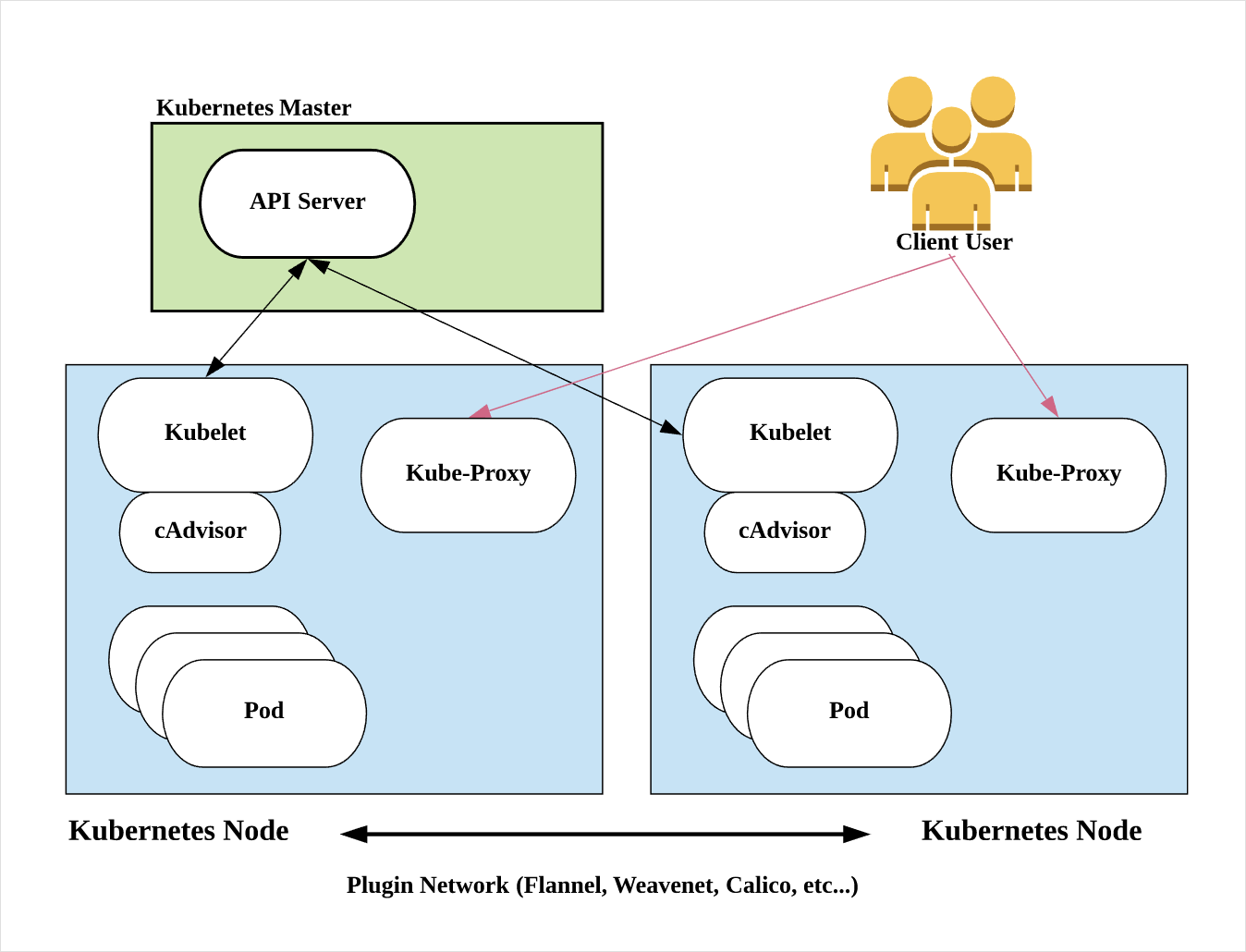
그림에서 컨테이너가 실행되는 worker 서버인 Kubernetes Node에 Pod이 여러개 들어있는 것을 볼 수 있다.
Pod을 알맞은 Node에 효율적으로 배치하고, 사용자가 기대하는 상태로 문제없이 실행되도록 Pod이 죽으면 다시 살려주거나, Node가 죽으면 기존 Node의 Pod을 다른 건강한 Node에 배치하는 등 Pod의 라이프 사이클을 관리하는 것이 K8s의 가장 큰 역할 중 하나라고 볼 수 있다.
Pod의 특징
Pod은 다음과 같은 특징을 가지고 있다.
- 1개의 Pod은 내부에 여러개의 컨테이너를 가질 수 있지만 대부분 1~2개의 컨테이너를 갖게 된다.
스케일링 또한 컨테이너가 아닌 Pod단위로 수행되기 때문에 Pod내부에 다수의 컨테이너들이 타이트하게 묶여있으면 스케일링이 쉽지 않거나 비효율적으로 이뤄지는 문제가 있다.
보통 Pod에는 메인 컨테이너 하나만 존재하거나, 메인 컨테이너에 반드시 묶여야 하는 Side Car격의 컨테이너를 같이 넣어 사용하게 된다. - 영한사전에서 Pod을 찾아보면 (새·바다표범·고래 등의) 작은 떼 라는 의미를 가진다.
Docker 컨테이너가 고래 모양의 심볼을 갖는 것을 생각해보면 고래(컨테이너)들의 떼를 Pod이라는 이름으로 칭한 것에 대해 납득이 간다. - 1개의 Pod은 여러개의 물리서버에 나눠지는 것이 아니고 1개의 물리서버(Node) 위에서 실행된다.
- 동일 작업을 수행하는 Pod은 ReplicaSet이라는 컨트롤러에 의해 정의된 룰에 따라 복제생성된다. 이때 복수의 Pod이 Master의 Scheduler에 의해 여러개의 Node에 걸쳐 실행될 수 있다.
- Pod은 클러스터 내에서 사용할 수 있는 유니크한 네트워크 ip를 할당 받지만 이 ip는 서비스에서 사용하지 않는다.
이는 K8s에서 Pod은 언젠가는 반드시 죽는(mortal) 오브젝트이기 때문이다.이후에 설명하겠지만 Service라는 오브젝트가죽기도하고 또 다시 살아나기도 하는 Pod의 Endpoint를 관리하고 Pod의 외부에서는 이 ‘Service’ 를 통해 Pod에 접근하게 된다. Service를 Pod에 연결했을 때 Pod의 특정 포트가 외부로 expose된다고 이해하면 될 것 같다. - Pod 내부의 컨테이너들은 네트워크와 볼륨 등을 공유하고 서로 localhost로 통신할 수 있다.
Pause 컨테이너
앞에서 Pod 내부의 컨테이너들은 네트워크와 볼륨을 공유하고 서로 localhost로 통신할 수 있다고 했다.
좀 더 자세히 들어가면 Pod이 실행될 때 pause 라는 이름의 컨테이너가 먼저 실행되고 이 pause컨테이너의 namespace를 Pod내부의 모든 컨테이너들이 공유해서 사용하게 된다.
여기서 말하는 namespace는 K8s Cluster를 논리적으로 구분해 사용하기 위한 Namespace가 아니다.
컨테이너를 기술적으로 구현하기 위해 사용하는 cgroups, namespace에서의 namespace를 의미한다.
간단히 설명하면, cgroups는 호스트의 자원을 제한해서 각 컨테이너에 할당하는 역할을 하고
namespace는 각 컨테이너가 컨테이너 외부와 격리된 IPC, Network, PID, File System을 가질 수 있게 독립적인 공간을 논리적으로 형성해준다.
pause 컨테이너는 단순히 namespace를 공유하기 위한 컨테이너이며 SIGINT나 SIGTERM 시그널을 받기 전까지 아무런 동작도 하지 않고 sleep 상태로 대기한다.
여기에 더해 Pod 실행 시 shared-pid 옵션이 enable로 설정되어 있는 경우
Pod 내부의 컨테이너 프로세스가 좀비 프로세스가 되지 않도록 pause 컨테이너는 PID 1로 설정되어 모든 컨테이너 프로세스의 부모 프로세스가 되고, 컨테이너 프로세스에 문제가 발생해 SIGCHLD 시그널을 받으면 waitpid(해당 프로세스 ID)를 수행해서 중지된 컨테이너가 사용하던 자원을 회수하는 역할도 수행하게 된다.
pause 컨테이너를 통해 namespace를 공유함으로서 Pod 내부의 컨테이너들은 Pod외부와 격리된 컨테이너의 장점을 유지하면서, Pod 내부에서는 자원을 공유하는 프로세스를 여러개의 컨테이너로 실행할 수 있다는 장점을 갖게된다. IPC, Network, PID, File System등이 동일한 namespace를 통해 공유되므로 Pod내부의 프로세스들은 localhost에 접근하듯 서로에 접근할 수 있게 되는 것이다.
이는 외부와 격리된 몇개의 도커 컨테이너를 동일한 namespace로 묶어 사용하는 기존의 아키텍처를 Pod이라는 이름으로 재 정의해서 사용하는 것일 뿐 특별히 새로운 개념은 아니다. 이 아키텍처를 클러스터의 기본 구성으로 가져가기 위해서 K8s의 가장 작은 배포단위를 컨테이너가 아닌 Pod으로 규정하는 것이다.
좀 더 구체적인 설명은 The Almighty Pause Container에서 확인할 수 있다.
K8s 테스트 환경 구성
설명만 들어서는 아직 감이 잘 오지 않는다. K8s 클러스터에 Pod을 한개 올려보자.
K8s 클러스터에 명령을 전달하기 위해서는 K8s API를 이용해야 하는데, K8s는 콘솔 환경에서 K8s API를 호출할 수 있도록 kubectl (Kubernetes command-line tool)을 제공한다.
나는 macOS 패키지 관리자인 brew를 이용해서 설치했다.
$ brew install kubectl
kubectl version 명령을 통해 설치가 잘 되었는지 확인해보자.
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"9", GitVersion:"v1.9.2", GitCommit:"5fa2db2bd46ac79e5e00a4e6ed24191080aa463b", GitTreeState:"clean", BuildDate:"2018-01-18T10:09:24Z", GoVersion:"go1.9.2", Compiler:"gc", Platform:"darwin/amd64"}
Error from server (Forbidden): unknown
Client는 정상적으로 설치되어 버전이 출력되는데, Server는 Error from server (Forbidden): unknown 오류가 발생한다.
kubectl이 접속할 대상서버(K8s 클러스터의 마스터 API Server)가 존재하지 않기 때문이다.
테스트를 위해서 K8s 클러스터 환경을 구성해야 하는데 GCP, AWS 등의 퍼블릭 클라우드는 과금의 부담이 있기 때문에 개념을 익히는 동안에는 로컬 환경을 구성해서 테스트 해보는 것이 좋겠다.
조만간 AWS위에 K8s 클러스터를 셋업하는 글을 작성할 예정이다. (정말!)
나는 Docker(for Mac)의 Edge(Community Edition) 버전에서 제공하는 K8s 클러스터를 사용하고 있다.
[ 주의 | 경고 | 위험 ]
Stable 버전의 Docker를 Edge 버전으로 전환할 경우 로컬에 받아놓은 이미지가 전부 삭제될 수 있음으로 Edge버전 설치 시 주의해야 한다.
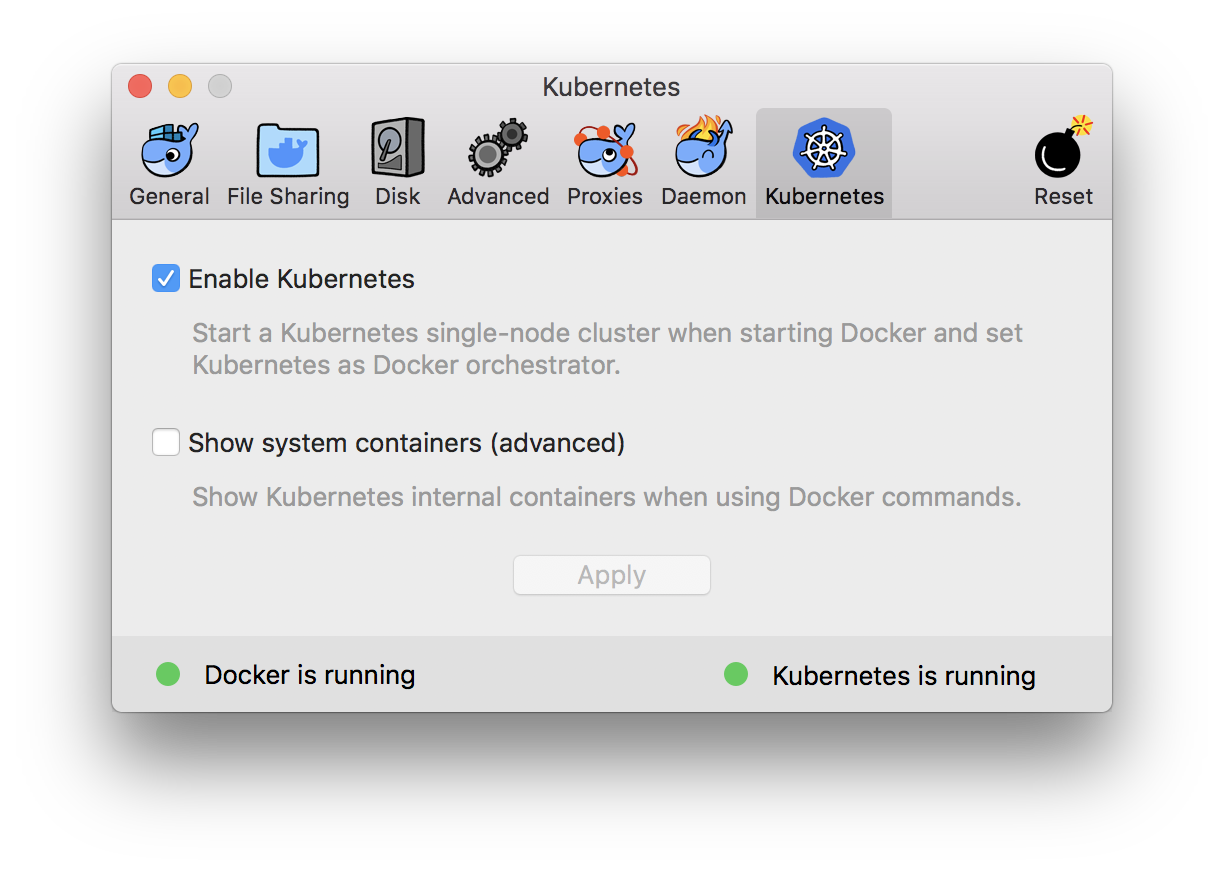
Docker for Mac의 클러스터는 로컬 테스트용으로 Master와 Node가 단일Node에 구성되어 있다.
kubectl get nodes 명령으로 노드 리스트를 출력해보자.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
docker-for-desktop Ready master 11d v1.9.2
테스트에 사용하는 K8s 클러스터는 다음과 같이 Reset 메뉴의 Reset Kubernetes cluster 버튼을 통해서 언제든 초기화할 수 있으니 안심하고 마음 편히 사용해보자.
K8s 서버를 실행하고 다음과 같이 터미널에서 kubectl version을 실행했을 때 Client와 Server의 버전이 정상적으로 출력되는 상태가 준비되어야 한다.
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"9", GitVersion:"v1.9.2", GitCommit:"5fa2db2bd46ac79e5e00a4e6ed24191080aa463b", GitTreeState:"clean", BuildDate:"2018-01-18T10:09:24Z", GoVersion:"go1.9.2", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"9", GitVersion:"v1.9.2", GitCommit:"5fa2db2bd46ac79e5e00a4e6ed24191080aa463b", GitTreeState:"clean", BuildDate:"2018-01-18T09:42:01Z", GoVersion:"go1.9.2", Compiler:"gc", Platform:"linux/amd64"}
Docker for Mac에서는 다음과 같이 상태를 확인할 수 있다.
Pod을 생성해보자.
우리가 처음 생성할 Pod은 8080포트로 HTTP GET 요청을 보내면 Hello World!를 리턴한다.
테스트를 위해 간단하게 작성된 hello-node 프로젝트를 Docker 이미지로 만들어 Docker Hub에 push 했다.
아래와 같이 docker run 명령을 사용해서 동작을 확인해 볼 수 있다.
$ docker run -d -p 8080:8080 asbubam/hello-node
d3e4902c8140a29d0f5a87d267f7d72bb568f7d03b026831036d2e9071e80e16
$ curl http://localhost:8080
Hello World!
Pod은 kubectl run 명령을 통해서 실행할 수도 있지만, yaml 파일을 사용해서 Pod을 정의하고 수정사항을 적용하면서 계속 설명을 진행하겠다. 실제 K8s 클러스터를 사용할 때도 yaml파일을 계속 작성하고 또 업데이트하는 작업을 반복하게 될 것이다.
다음은 hello-node Pod을 정의한 hello-node.yml 파일이다.
apiVersion: v1
kind: Pod
metadata:
name: hello-node
labels:
service-name: hello-node
spec:
containers:
- name: hello-node
image: asbubam/hello-node
readinessProbe:
httpGet:
path: /
port: 8080
livenessProbe:
httpGet:
path: /
port: 8080
---
apiVersion: v1
kind: Service
metadata:
name: hello-node
spec:
type: LoadBalancer
ports:
- port: 8080
targetPort: 8080
selector:
service-name: hello-node
자세한 내용 설명은 이후에 하기로 하고 우선 Pod을 생성해보자.
# kubectl get pods 명령으로 Pod list를 조회해보면 아직 아무것도 없다.
$ kubectl get pods
No resources found.
# kubectl create -f {yaml 파일명} 으로 Pod을 생성한다.
$ kubectl create -f hello-node.yml
pod "hello-node" created
service "hello-node" created
# kubectl get pods 결과에 1개의 Pod이 생성되고 있음을 확인할 수 있다.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-node 0/1 ContainerCreating 0
# Pod이 정상적으로 실행되면 잠시 후에 아래와 같이 STATUS가 Running으로 update된다.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-node 0/1 Running 0 13s
# localhost:8080에 접속해서 Hello World! 가 출력됨을 확인한다.
$ curl http://localhost:8080
Hello World!
Pod의 생성과 삭제 요청 시에 Pod만 생성되는 것이 아니라 Service가 같이 생성되는데, 외부에서 Pod에 접속하기 위해서는 Service나 Ingress Controller를 통해 Pod의 포트를 expose해줘야 한다. 이 부분에 대해서는 다음 글에서 계속 설명할 예정이니 여기서는 Pod에 대해서만 집중해서 살펴보자.
Pod이 생성되는 과정
kubectl create 명령으로 Pod 생성을 요청하면 다음과 같은 과정을 통해 Pod이 생성된다.
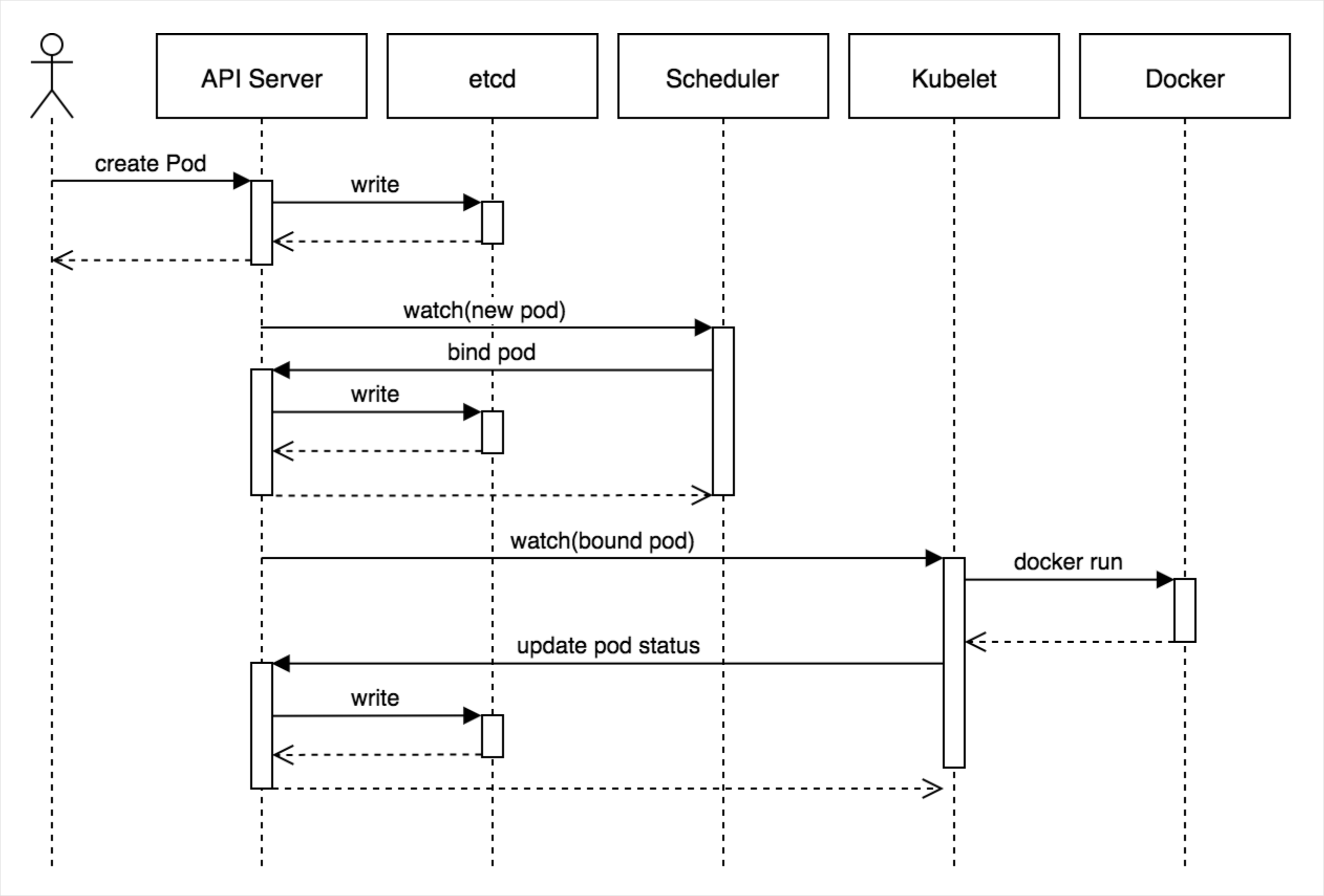
from: Core Kubernetes: Jazz Improv over Orchestration
- kubectl은 API Server에 Pod생성을 요청
- APIServer는 etcd에 Node에 할당되지 않은 Pod이 있음을 업데이트
- Scheduler는 etcd의 변경사항을 API Server를 통해 watch하고 Pod을 실행할 Node를 선택해 API Server에 해당 Node에 Pod을 배정하도록 업데이트
- 해당 Node의 Kubelet은 생성할 Pod정보를 watch해서 Docker 컨테이너를 실행하고 결과를 API Server에 지속적으로 업데이트
- API Server는 전달받은 Pod의 상태를 etcd에 업데이트
과정을 살펴보면 각 컴퍼넌트가 연결되는 형태가 아닌 API Server를 경유해서 etcd의 상태를 watch하고 변경사항을 적용 후 API Server를 통해 etcd에 업데이트 한다.
hello-node.yml 자세히 읽어보기
hello-node Pod 생성에 사용했던 hello-node.yml 파일의 각 항목에 대해 알아보자.
apiVersion: v1 # K8s api version, 특정 object는 v1beta를 사용한다.
kind: Pod # 생성할 object, controller의 종류
metadata:
name: hello-node # object의 고유 이름, 복수로 생성할 경우 prefix로 사용된다.
labels: # 외부에서 Pod을 찾을 때 사용할 label. 복수의 label 입력가능
service-name: hello-node
spec: # 기대되는 obejct의 상태
containers: # Pod 내부에서 생성할 컨테이너 목록
- name: hello-node # 컨테이너 이름
image: asbubam/hello-node # 컨테이너를 실행할 이미지
readinessProbe:
httpGet: # health check 방법 exec, httpGet, tcpSocket
path: / # health check path
port: 8080 # health check port
livenessProbe:
httpGet:
path: /
port: 8080
--- # 주석 한개의 yaml파일에 여러개의 Object를 정의할 때 구분자로 사용한다.
# Service Object 정의 - 다음 글에서 자세히 설명한다.
apiVersion: v1
kind: Service
metadata:
name: hello-node
spec:
type: LoadBalancer # 외부에 Pod을 어떤 형태로 노출할지 결정
ports:
- port: 8080 # 외부에 노출할 포트
targetPort: 8080 # 컨테이너의 포트
selector:
service-name: hello-node # Service가 연결할 대상 Pod의 label
- spec은 글의 시작부분에서 설명했던 object의 필수 필드인 Spec, Status 중 Spec(Desired State)을 의미한다.
- metadata의 labels는 외부에서 해당 object를 select 할 때 사용된다. hello-node.yml 에서는 Service가 연결할 대상 Pod을 찾을 때 service-name label의 값이 hello-node인 Pod을 찾아 연결하게 된다.
- Pod의 health check를 위해 readinessProbe, livenessProbe 항목을 사용한다.
여기서 readiness는 외부로 부터 트래픽을 받을 준비가 되었는 지를 의미하고 liveness는 컨테이너가 정상적으로 살아있는 지를 의미한다.
readiness가 정상이 아닌 경우 해당 컨테이너는 외부의 트래픽을 받지 않도록 제외되고, liveness가 정상이 아닌 경우 해당 컨테이너는 정해진 룰에 따라 중지 -> 재 실행된다. - readinessProbe, livenessProbe에서 exec타입은 커맨드 명령을 수행하고 그 결과 리턴 값이 0이 아닌 경우 health check 실패로 판단한다.
- readinessProbe, livenessProbe에는 다음과 같은 optional 필드를 입력받을 수 있다.
initialDelaySecond : 컨테이너가 실행되고 첫 Probe체크를 할 때까지의 delay (default: 0)
periodSeconds : 체크 주기 (default 10초, min 1초)
timeoutSeconds : Probe 체크 timeout (default: 1초, min 1초)
successThreshold : Probe 체크 실패 시 Threshold만큼 다시 체크에 성공해야 success로 판단 (default: 1)
failureThreshold : Probe 체크 실패 시 Threshold만큼 재 시도 하고 체크 포기 (default: 3)
readness의 경우 트래픽 대상에서 제외, liveness의 경우 컨테이너 재시작 - Pod이 사용할 리소스의 limit도 제한할 수 있다.
아직은 yaml 파일의 내용이 많이 낯설지만, 앞으로 하나씩 object, controller를 정의해 가면서 익숙해 질 것으로 생각한다. 여기서는 “이런 내용이 있군.” 하고 훑어보는 정도로 충분할 것 같다.
Pod 관련 kubectl 명령
kubectl get | create 외에도 다음과 같은 명령이 제공된다. 해당 명령들은 모두 Master의 API Server의 API를 호출하기 때문에 이 명령들은 Dashboard UI나 API를 직접호출하는 방식으로도 실행 가능하다.
kubectl describe pod: 상세한 Pod의 현재 상태, 발생한 이벤트 기록을 조회한다.
$ kubectl describe pod hello-node
Name: hello-node
Namespace: default
Node: docker-for-desktop/192.168.65.3
Start Time: Wed, 28 Mar 2018 00:32:10 +0900
Labels: service-name=hello-node
Annotations: <none>
Status: Running
IP: 10.1.0.223
Containers:
hello-node:
Container ID: docker://5eeb6f90d7cef6ba4fb89e542801356b5d8695246a3a2fb27cbd935ee151ea3a
Image: asbubam/hello-node
Image ID: docker-pullable://asbubam/hello-node@sha256:3d7137c208e1f3cccbd64a206d178751d0a1df07f6e5faf6fa9419454fa349a8
Port: <none>
State: Running
Started: Wed, 28 Mar 2018 00:32:16 +0900
Ready: True
Restart Count: 0
Liveness: http-get http://:8080/ delay=0s timeout=1s period=10s #success=1 #failure=3
Readiness: http-get http://:8080/ delay=0s timeout=1s period=10s #success=1 #failure=3
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-brzzw (ro)
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
default-token-brzzw:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-brzzw
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 1m default-scheduler Successfully assigned hello-node to docker-for-desktop
Normal SuccessfulMountVolume 1m kubelet, docker-for-desktop MountVolume.SetUp succeeded for volume "default-token-brzzw"
Normal Pulling 1m kubelet, docker-for-desktop pulling image "asbubam/hello-node"
Normal Pulled 1m kubelet, docker-for-desktop Successfully pulled image "asbubam/hello-node"
Normal Created 1m kubelet, docker-for-desktop Created container
Normal Started 1m kubelet, docker-for-desktop Started container
kubectl logs: 컨테이너 로그를 확인할 수 있다. (복수의 컨테이너가 실행 중일 때 -c 옵션으로 특정 컨테이너 지정가능)
$ kubectl logs hello-node
npm info it worked if it ends with ok
npm info using npm@3.10.10
npm info using node@v6.10.3
npm info lifecycle hello-node@0.0.1~prestart: hello-node@0.0.1
npm info lifecycle hello-node@0.0.1~start: hello-node@0.0.1
> hello-node@0.0.1 start /usr/src/app
> node server.js
hello-node app listening on port 8080
kubectl exec: Pod 컨테이너에 명령을 수행한다. (복수의 컨테이너가 실행 중일 때 -c 옵션으로 특정 컨테이너 지정가능)
$ kubectl exec -it hello-node ps aux | grep server.js
root 16 0.0 1.4 885468 29840 ? Sl 15:32 0:00 node server.js
# 컨테이너의 shell에 접속
$ kubectl exec -it hello-node sh
# exit
command terminated with exit code 127
kubectl delete pod: Pod 삭제
# Pod name을 사용해서 Pod을 삭제
$ kubectl delete pod hello-node
pod "hello-node" deleted
# yaml파일을 사용해서 Pod을 삭제
$ kubectl delete -f hello-node.yml
pod "hello-node" deleted
service "hello-node" deleted
정리
K8s의 Pod object에 대해서 알아봤다. 이 장에서는 K8s의 가장작은 배포단위가 컨테이너가 아닌 Pod이라는 점. 그리고 Pod은 언제든 죽을 수 있는 존재이며 K8s에 의해 사용자가 기대하는 상태로 생성, 유지된다는 점을 기억하면 좋을 것 같다.
Pod 만으로는 아직 K8s에 대해서 이해가 쉽지 않다. 논리적으로 클러스터를 분리하는 Namespace, Pod을 복제/실행하는 ReplicaSet, Pod의 배포를 정의하는 Deployment, 외부에서 들어오는 요청을 Pod에 연결해주는 Service, Ingress Controller등에 대해서 하나씩 설정을 추가해가며 설명을 이어나갈 예정이다.
어느정도 개념이 정리되면 AWS에 K8s 클러스터를 구성하는 방법에 대해 설명하고 AWS 환경에서 작은 서비스를 올려가는 과정을 연재하려고 한다. (그동안 많이 쉬었으니까 이제 쉼없이 달려야…)
덧붙여…
블로그를 쉬는 동안 Patreon 사이트에서 블로그 연재를 위한 후원을 받았다. 블로그 작성을 위해 사용하는 AWS 리소스 비용이 부담되기도 했지만, 그것보다는 스스로에게 좀 더 동기부여가 되었으면 하는 소망이 더 컸던 것 같다.
감사하게도 글을 쓰는 현재 열세 명의 후원자분들이 43달러를 후원해주셨다. 여기에는 물론 지인들도 있었지만, 트위터 등의 링크를 통해서 내 블로그를 보고 계셨던 분들이 내가 쓰는 글이 도움이 된다며 응원의 메시지와 함께 후원을 해주시기도 했다. AWS Korea의 윤석찬님도 후원을 해주셨다.
별로 대단한 내용도 아닌데, 잘 모르는 분야에 대해서 공부해가며 글을 쓰다보니 글을 쓰기 시작해서 마무리가 될때까지 시간이 많이 걸리는 편이다. 쉬는 기간 어느정도 예습을 끝냈으니 이제 속도를 높여서 계속 글을 이어나가려고 한다. 여기까지 읽어주신 분이라면 앞으로의 글도 기대하고 응원해주시면 더 힘이 날 것 같다. 🙂
참고자료
- Pod Overview – Kubernetes Concepts
- Understanding Kubernetes Objects – Kubernetes Concepts
- Kubernetes in 5 mins – VMware Cloud-Native
- The Almighty Pause Container
- Core Kubernetes: Jazz Improv over Orchestration
- Pod Lifecycle – Kubernetes Concepts
One thought to “Kubernetes 01 – Pod”
Comments are closed.