![]()
Kubernetes(쿠버네티스)는 Docker, rkt container를 위한 Open Source Orchestration System 입니다.
약 10여년 전, 구글이 Container Management를 위해 개발한 Borg를 시작으로 Omega를 거쳐 Kubernetes가 탄생하게 됩니다. Kubernetes가 사용하는 Pod, Service, Label, IP-per-pod model 개념등이 Borg에서 시작되었습니다.
Kubernetes는 그리스어로 배의 조타수를 의미 (영문 표기로는 Helmsman)
K와s 사이의 8글자를 생략해서 K(ubernete)s = K8s라고 표기하기도 함
2014년 Google에서 개발시작, 2015년 7월 첫 릴리즈
2016년 Cloud Native Computing Foundation(Linux Foundation)에 기부
100% Open Source, Go 언어로 개발
2017년 3월 현재 v1.4.9 (v1.6.0-beta.1)
아래 1분 30초 분량의 동영상을 통해서 Container Orchestration이 왜 필요한지, Kubernetes의 역할이 무엇인지 이해해 봅시다!
- Udacity의 Scalable Microservices with Kubernetes by Google 강의 중 일부분입니다.
from https://www.youtube.com/embed/gOnzr-DIVJ8?&cc_load_policy=1
특징
-
Automatic binpacking
가용성을 희생하지 않는 범위안에서 리소스를 충분히 활용해서 Container를 배치합니다. -
Self-healing
Container의 실행 실패, node가 죽거나 반응이 없는 경우, health check에 실패한 경우에 해당 Container를 자동으로 복구합니다. -
Horizontal scaling
pod의 CPU사용이나 app이 제공하는 metric을 기반으로 ReplicaSet을 scaling할 수 있습니다. -
Service discovery and load balancing
익숙하지 않는 Service Discovery매커니즘을 위해 Application을 수정할 필요가 없습니다. Kubernetes는 Container에 고유 IP, 단일 DNS를 제공하고 이를 이용해 load balacing합니다. -
Automated rollouts and rollbacks
application, configuration의 변경이 있을 경우, 전체 인스턴스의 중단이 아닌, 점진적으로 Container에 적용(rolling update) 가능합니다. 변경내용이 문제 있을 경우 자동으로 Rollback을 진행할 수 있습니다. -
Secret and configuration management
Secret key, configuation을 이미지의 변경없이 업데이트할 수 있고, 외부로 노출(expose)하지 않고 관리/사용할 수 있습니다. -
Storage orchestration
local storage를 비롯해서 public cloud(GCP, AWS), network storage등을 구미에 맞게 자동 mount할 수 있습니다. -
Batch Execution
batch, CI 작업의 수행을 관리할 수 있습니다. 원한다면 실패 시 container를 replace하는 것도 가능합니다.
아키텍쳐
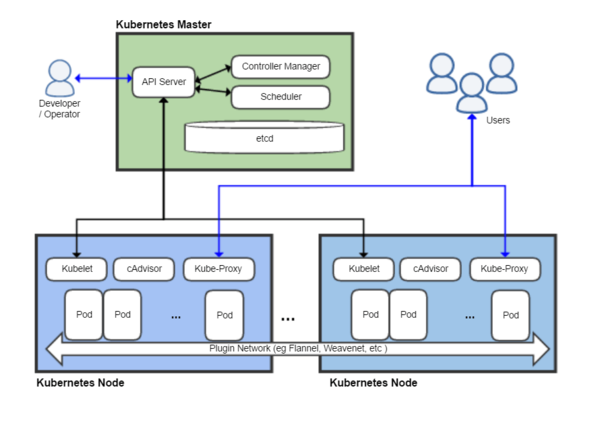
from https://en.wikipedia.org/wiki/Kubernetes
Kubernetes에서는 Kubernetes Master와 1개 이상의 (worker) node로 이뤄진 가상/물리 머신의 Set를 통해 Cluster가 구성됩니다.
Kubernetes v1.5(alpha)부터 Master의 replication(Google Compute Engine only)을 지원하기 시작했습니다.
주요 키워드
- Kubernetes Master
Kubernetes Cluster의 main component입니다.- API server (kube-apiserver)
Kubernetes Components(kubectl, scheduler, replication controller, etcd datastore, kubelet, kube-proxy…)들의 hub로서 HTTP, HTTPS 기반의 RESTFul API를 제공합니다. -
Scheduler (kube-scheduler)
어떤 Container가 어떤 Node에서 실행될지 결정합니다.
CPU, Memory, 얼마나 많은 Container가 해당 Node에서 작동 중인가에 기반한 간단한 알고리즘으로 Container를 배치합니다. -
Controller manager (kube-controller-manager)
Kubernetes node를 관리합니다.
Kubernetes internal information을 생성하고 갱신합니다.
Container의 상태를 기대하는 상태로 변경합니다. -
etcd storage
shared configuration, namespace, replication information등
pod/service의 세부사항, 상태 저장 및
service discovery를 위해 skydns를 기반으로한 DNS 데이터 저장에 사용됩니다.
- API server (kube-apiserver)
-
Kubernetes Node – minion
Kubernetes cluster의 slave(work) node입니다.- kubelet
Kubernetes node의 main process.
Kubernetes master와 통신하며 다음의 동작을 수행합니다.- 주기적으로 API Controller에 check&report access합니다.
- container operation을 수행합니다.
- API제공을 위한 simple http 서버를 구동합니다.
- Proxy (kube-proxy)
- 각 container간의 network proxy와 load balancer를 핸들링합니다.
- container간의 TCP/UDP 패킷 송수신을 위해 Linux iptables rules(nat table)의 변경을 수행합니다.
- cAdvisor
- cAdviser(Container Advisor)는 동작중인 container의 resource 사용량과 performance에 대해 분석/제공합니다.
- kubelet
- Container
우리가 아는 그 Docker/rkt Container 입니다. -
Pod
deployable unit의 가장작은 단위
container의 묶음
pod내부의 container들은 network와 data volume을 공유합니다.
Pod내부의 container들은 localhost로 서로에 접근가능합니다.
라우팅 가능한 IP를 부여받습니다. -
Service
Persistent Endpoint for Pods
Pod의 lifetime은 짧고 mortal(언젠간 죽어요)합니다.
Pod이 몇개가 존재하던, Service가 Pod묶음의 proxy로서 존재합니다.
Service는 Pod에 Virtual IP, DNS name을 제공하고 label selector를 통해 Pod을 구분합니다.
Service는 요청을 받아 Pod에 load balancing하게 됩니다. -
Replication Controller
pod 복제에 사용하는 pod template 를 제공합니다.
pod의 scaling logic을 제공합니다.
Replication Controller를 통해 rolling deploy가 가능하게 됩니다.
여기서 아키텍쳐를 한번 더 복습!
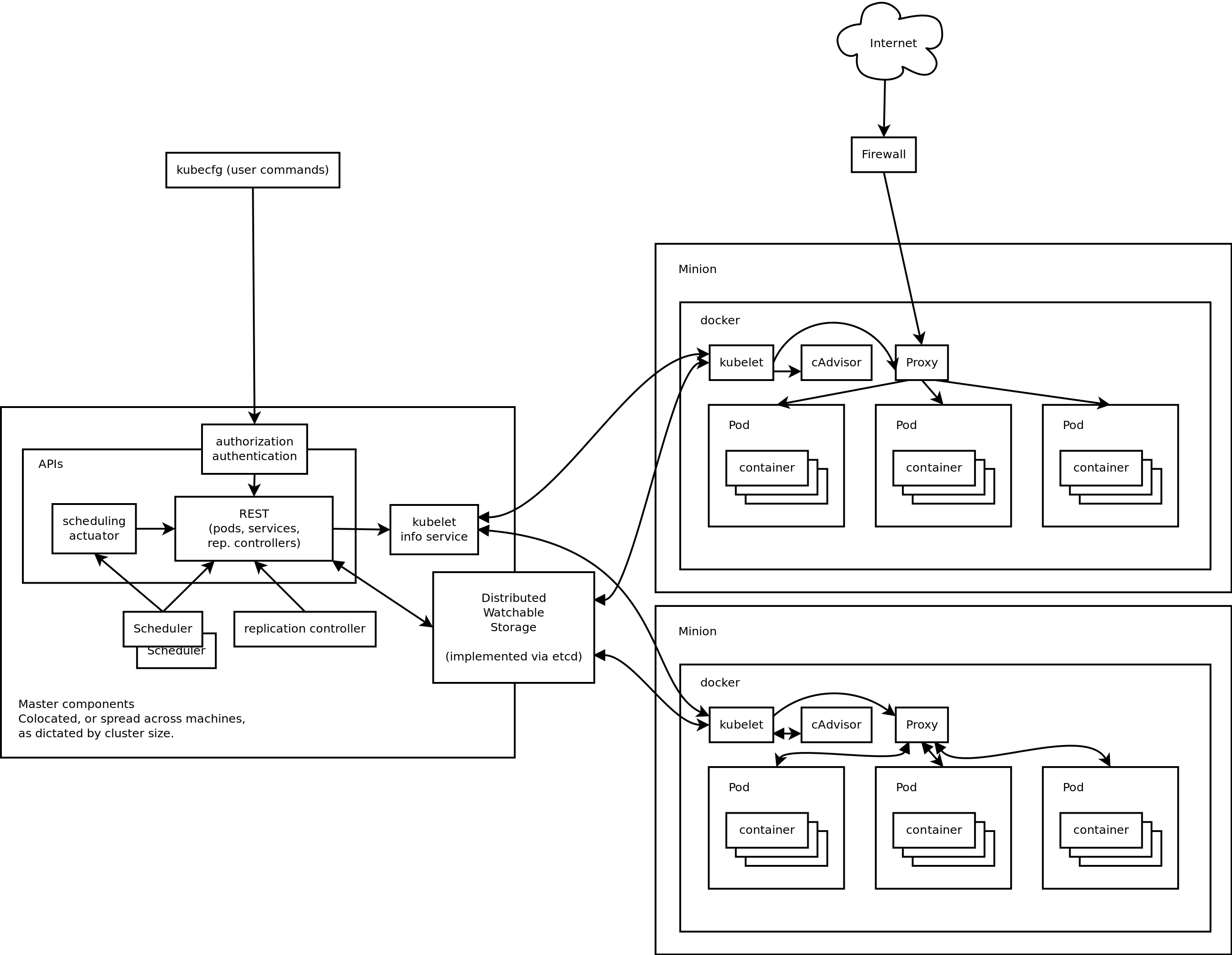
from http://blog.arungupta.me/key-concepts-kubernetes/
- ReplicaSets
pod의 run * copies(replicas)
health check를 통해 pod의 상태를 체크합니다.
pod의 상태가 불량할 경우, 재 시작합니다. -
deployment
Drive current state towards desired state
rolling update, rollback을 지원하는 pod, replica set -
Label
Kubernetes는 Label을 Kubernetes가 사용하는 각각Object를 분류하는 nametag로 사용합니다.
내부적으로 Selector가 이 Label을 사용해서 query합니다.. -
Selector

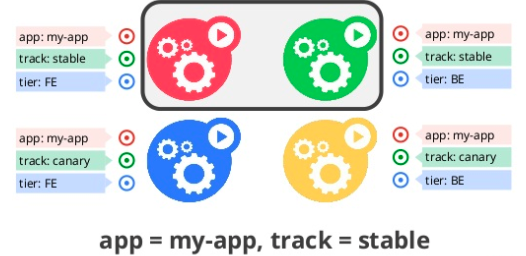
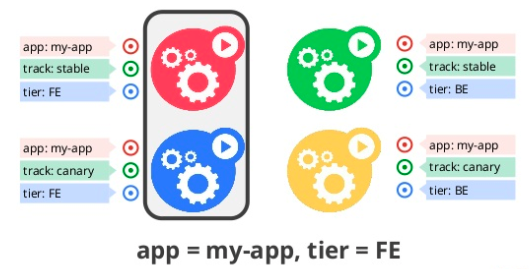
from WSO2Con US 2015 Kubernetes: a platform for automating deployment, scaling, and operations -
Volume
pod은 volume을 filesystems처럼 마운트 할 수 있습니다.
empty directory, host directory, Google Persistent Disk, Amazon Blob Store, NFS, glusterfs, rdb, cephs, git repository 등을 Volume으로 사용할 수 있습니다. -
Namespace
pod, replicasets, volume등을 그룹핑합니다.
각각의 pod, replication controller, volume, secret을 구분하는데 사용합니다.
더 알고싶은 키워드
-
PetSets
Pet is a stateful pod
Pet is bound to a dynamically created data volume that data volume will nerver be deleted automatically.
the Pet is bound to the same volume on a restart -
Jobs
run short living tasks
retry on failure
ScheduledJobs can be started at specific times(like cron) -
DaemonSets
DaemonSets run pods on all (or a selected set of) nodes in the cluster
userfule for running containers for logging and monitoring -
Secrets and ConfigMaps
separate your application code(=images) and configuration
both Secrets and ConfigMaps are key-value-pairs
use Secrets for binary values
use ConfigMaps for string values
both can be read by the container via environment variables or mapped into a data volume like property files.
API
- Kubernetes는 모든 function을 REST API로 제공합니다.
- API를 통해 기존의 CI/CD workflow에 쉽게 적용할 수 있습니다.
- CLI툴인 kubectl 역시 내부적으로 REST API를 사용합니다.
Service Discovery
Kuberentes는 Environment Variables 와 DNS(skydns based)의 2가지 방법을 통해서 Service Discovery할 수 있습니다. Enviroment Variables를 사용하는 경우, Pod이 생성되기 전에 미리 선언을 해야하는 등 순서에 따른 문제가 발생할 수 있어, DNS 사용을 통한 Service Discovery방식을 추천하고 있습니다.
Scaling
- Horizontal Pod Autoscaling
pod의 CPU사용이나 app이 제공하는 metric을 기반으로 ReplicaSet을 scaling
# Scale a replicaset named 'foo' to 3.
$ kubectl scale --replicas=3 rs/foo
# Scale a resource identified by type and name specified in "foo.yaml" to 3.
$ kubectl scale --replicas=3 -f foo.yaml
# If the deployment named mysql's current size is 2, scale mysql to 3.
$ kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
# Scale multiple replication controllers.
$ kubectl scale --replicas=5 rc/foo rc/bar rc/baz
# Scale job named 'cron' to 3.
$ kubectl scale --replicas=3 job/cron
# create an autoscaler for replication controller foo, with target CPU utilization set to 80% and the number of replicas between 2 and 5.
$ kubectl autoscale rc foo --min=2 --max=5 --cpu-percent=80
- Cluster Autoscaling
CPU, memory 사용량을 기반으로 cluster의 node개수를 scaling
cloud provider에 의존합니다.
Network
https://kubernetes.io/docs/admin/networking/
Mornitoring & Logging
https://kubernetes.io/docs/concepts/clusters/logging/
그 밖의 이야기
- Magic of Kubernetes
https://medium.com/spire-labs/mitigating-an-aws-instance-failure-with-the-magic-of-kubernetes-128a44d44c14
Kubernetes + kops의 조합으로 얼마전 있었던 AWS us-east-1 장애를 다운타임없이 대처할 수 있었다는 마법같은 이야기With Kubernetes, there was never a moment of panic, just a sense of awe watching the automatic mitigation as it happened. Kubernetes immediately detected what was happening. It created replacement pods on other instances we had running in different availability zones, bringing them back into service as they became available.
All of this happened automatically and without any service disruption, there was zero downtime

-
kops – Kubernetes Operations
https://github.com/kubernetes/kops
https://github.com/kubernetes/kops/blob/master/docs/aws.md
production-grade의 Kubernetes Cluster deploy를 자동화합니다. 현재는 AWS만 지원하고, 다른 플랫폼도 계획중이라고 합니다. -
helm – The Kubernetes Package Manager
https://github.com/kubernetes/helm
https://github.com/kubernetes/helm/blob/master/docs/using_helm.md
pre-configured된 Kubernetes resources를 Chart라 하는데, 이 Chart를 helm명령어로 쉽게 설치/사용/관리할 수 있게 도와줍니다. -
Awesome-Kubernetes
https://www.gitbook.com/book/ramitsurana/awesome-kubernetes/details
kubernetes관련 awesome한 링크 모음집 -
Scalable Microservices with Kubernetes by Google
https://www.udacity.com/course/scalable-microservices-with-kubernetes–ud615
quora에 kubernetes를 배우는 좋은 방법으로 검색했더니 답변에 자주 언급되었던 udacity무료강의
참고자료
- Scalable Microservices with Kubernetes by Google
- WSO2Con US 2015 Kubernetes: a platform for automating deployment, scaling, and operations
- 15 Kubernetes features in 15 minutes by Marc Sluiter
- 구글이 만든 Docker Container Orchestration 툴, Kubernetes 소개
- Borg: The Predecessor to Kubernetes
- kubectl Cheat Sheet
2 thoughts to “Kubernetes”
Comments are closed.